[TOC]
进程管理
进程、线程基础知识
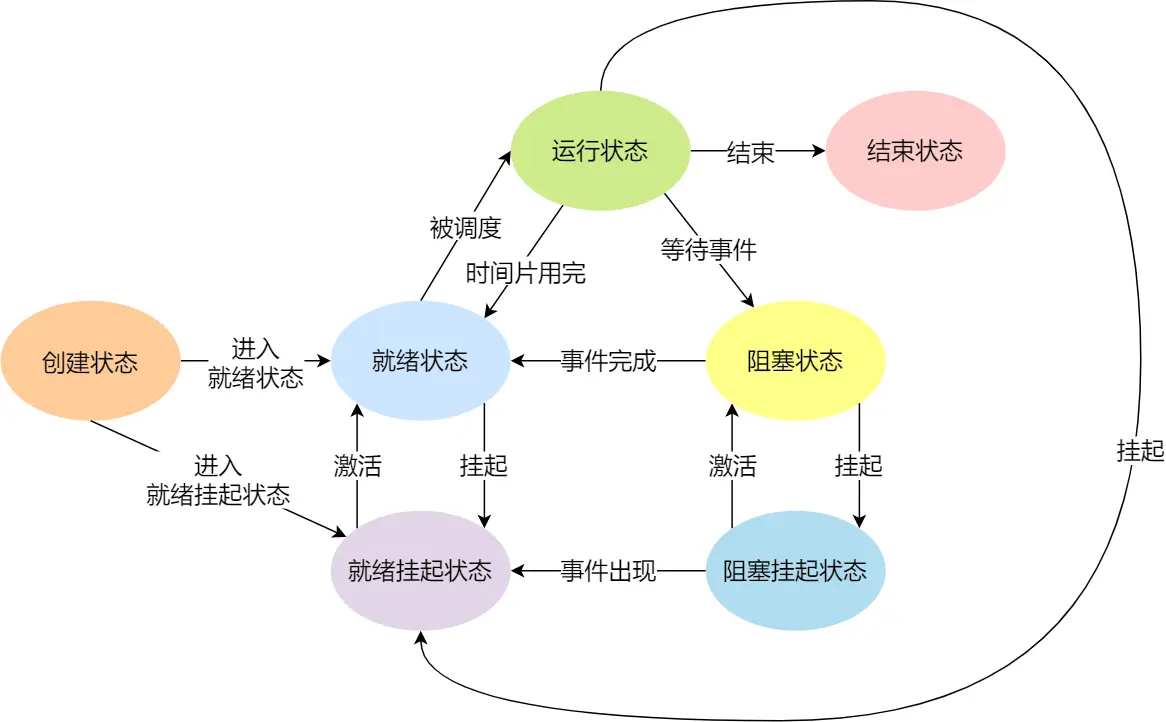
描述进程没有占用实际的物理内存空间的情况,这个状态就是挂起状态。
导致进程挂起的原因不只是因为进程所使用的内存空间不在物理内存,还包括如下情况:
通过 sleep 让进程间歇性挂起,其工作原理是设置一个定时器,到期后唤醒进程。
用户希望挂起一个程序的执行,比如在 Linux 中用 Ctrl+Z 挂起进程;
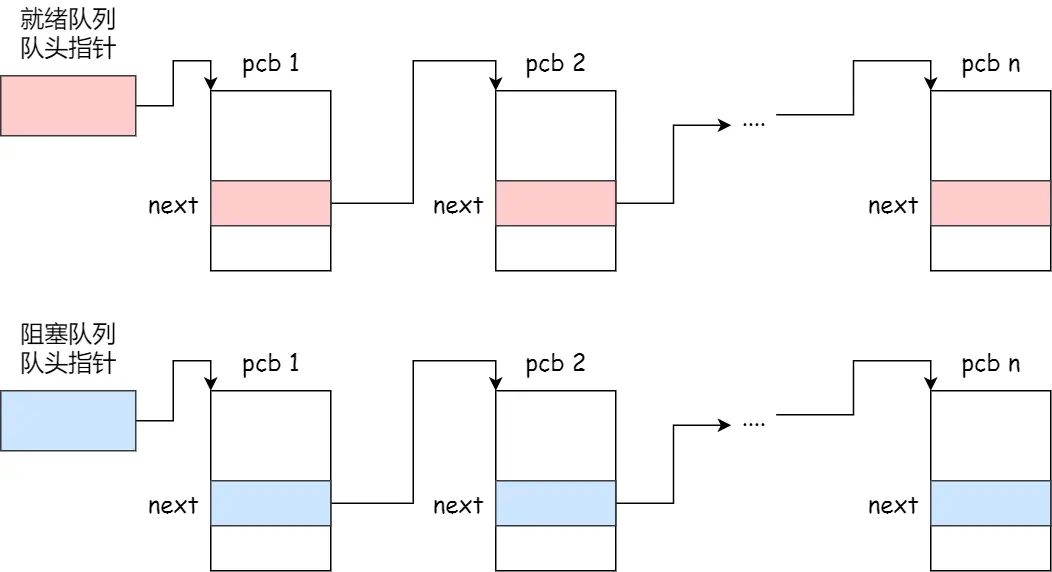
在操作系统中,是用进程控制块(process control block,PCB)数据结构来描述进程的。
PCB 是进程存在的唯一标识,这意味着一个进程的存在,必然会有一个 PCB,如果进程消失了,那么 PCB 也会随之消失。
CPU 寄存器是 CPU 内部一个容量小,但是速度极快的内存(缓存)。
CPU 寄存器和程序计数是 CPU 在运行任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下文。
可以根据任务的不同,把 CPU 上下文切换分成:进程上下文切换、线程上下文切换和中断上下文切换。
进程的切换只能发生在内核态。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
发生进程上下文切换有哪些场景?
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,进程就从运行状态变为就绪状态,系统从就绪队列选择另外一个进程运行;
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行;
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度;
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;
线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。
主要有三种线程的实现方式:
- 用户线程(User Thread):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;多个用户线程对应同一个内核线程。
- 内核线程(Kernel Thread):在内核中实现的线程,是由内核管理的线程;一对一
- 轻量级进程(LightWeight Process):在内核中来支持用户线程;多对多
用户线程是基于用户态的线程管理库来实现的,那么线程控制块(Thread Control Block, TCB) 也是在库里面来实现的,对于操作系统而言是看不到这个 TCB 的,它只能看到整个进程的 PCB。
在 LWP 之上也是可以使用用户线程的,那么 LWP 与用户线程的对应关系就有三种:
- 1 : 1,即一个 LWP 对应 一个用户线程;
- N : 1,即一个 LWP 对应多个用户线程;
- M : N,即多个 LWP 对应多个用户线程;
五种调度原则,总结成如下:
- CPU 利用率:调度程序应确保 CPU 是始终匆忙的状态,这可提高 CPU 的利用率;
- 系统吞吐量:吞吐量表示的是单位时间内 CPU 完成进程的数量,长作业的进程会占用较长的 CPU 资源,因此会降低吞吐量,相反,短作业- 的进程会提升系统吞吐量;
- 周转时间:周转时间是进程运行+阻塞时间+等待时间的总和,一个进程的周转时间越小越好;
- 等待时间:这个等待时间不是阻塞状态的时间,而是进程处于就绪队列的时间,等待的时间越长,用户越不满意;
- 响应时间:用户提交请求到系统第一次产生响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准。
单核 CPU 系统中常见的调度算法:
- 先来先服务(First Come First Serve, FCFS)算法
- 最短作业优先(Shortest Job First, SJF)调度算法
- 高响应比优先 (Highest Response Ratio Next, HRRN)调度算法:每次进行进程调度时,先计算「响应比优先级」,然后把「响应比优先级」最高的进程投入运行,优先权=(等待时间+要求服务时间)/要求服务时间,高响应比优先调度算法是「理想型」的调度算法,现实中是实现不了的。
- 最古老、最简单、最公平且使用最广的算法就是时间片轮转(Round Robin, RR)调度算法
- 最高优先级(Highest Priority First,HPF)调度算法,优先级可以分为静态优先级和动态优先级
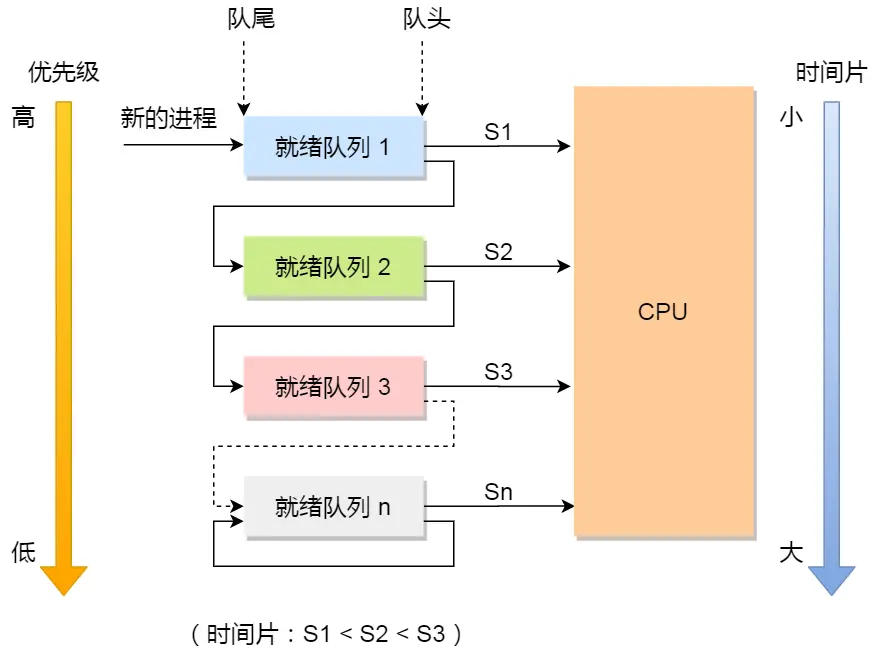
- 多级反馈队列(Multilevel Feedback Queue)调度算法是「时间片轮转算法」和「最高优先级算法」的综合和发展。
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从高到低,同时优先级越高时间片越短;
- 新的进程会被放入到第一级队列的末尾,按先来先服务的原则排队等待被调度,如果在第一级队列规定的时间片没运行完成,则将其转入到第二级队列的末尾,以此类推,直至完成;
- 当较高优先级的队列为空,才调度较低优先级的队列中的进程运行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行;
进程间通信
管道
ps auxf | grep mysql # 匿名管道
mkfifo myPipe # 创建命名管道,基于 Linux 一切皆文件的理念,所以管道也是以文件的方式存在
ls -l # 这个文件的类型是 p,也就是 pipe(管道) 的意思
echo "hello" > myPipe # 将数据写进管道,停住了 ...
cat < myPipe # 读取管道里的数据
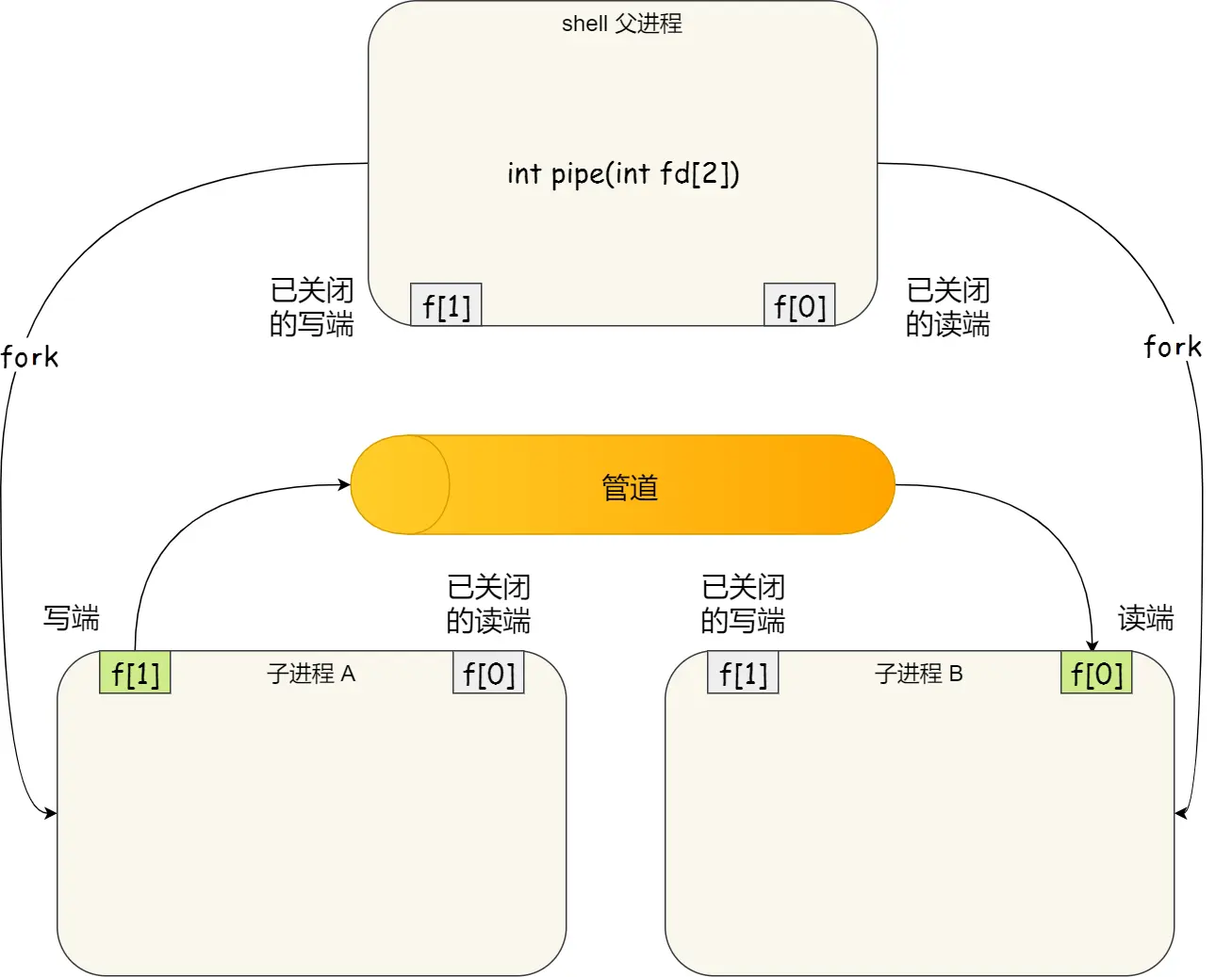
匿名管道的创建,需要通过下面这个系统调用:
int pipe(int fd[2])
管道的读取端描述符 fd[0],管道的写入端描述符 fd[1]
- 使用 fork 创建子进程,创建的子进程会复制父进程的文件描述符,父进程关闭读取的 fd[0],只保留写入的 fd[1];子进程关闭写入的 fd[1],只保留读取的 fd[0],使用管道进行父进程与子进程之间的通信;
- 在 shell 里面执行 A | B命令的时候,A 进程和 B 进程都是 shell 创建出来的子进程,A 和 B 之间不存在父子关系,它俩的父进程都-是 shell。
消息队列
消息队列是保存在内核中的消息链表,一是通信不及时,二是附件也有大小限制,消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销。
在 Linux 内核中,会有两个宏定义 MSGMAX 和 MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。
共享内存
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。
如果多个进程同时修改同一个共享内存,很有可能就冲突了。
信号量
- 一个是 P 操作,这个操作会把信号量减去 1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
- 另一个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
P 操作是用在进入共享资源之前,V 操作是用在离开共享资源之后,这两个操作是必须成对出现的。
初始化信号量为 1,使得两个进程互斥访问共享内存。
信号初始化为 0,就代表着是同步信号量,它可以保证进程 A 应在进程 B 之前执行。
信号
通过kill -l命令,查看所有的信号
Ctrl+C 产生 SIGINT 信号,表示终止该进程;
Ctrl+Z 产生 SIGTSTP 信号,表示停止该进程,但还未结束;kill -9 1050,表示给 PID 为 1050 的进程发送 SIGKILL 信号,用来立即结束该进程;
信号是进程间通信机制中唯一的异步通信机制。
用户进程对信号的处理方式。
- 执行默认操作。Linux 对每种信号都规定了默认操作,例如,上面列表中的 SIGTERM 信号,就是终止进程的意思。
- 捕捉信号。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
- 忽略信号。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
Socket
int socket(int domain, int type, int protocal)
domain 参数用来指定协议族,type 参数用来指定通信特性,protocal 参数原本是用来指定通信协议的,但现在基本废弃。
监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作监听 socket,一个叫作已完成连接 socket。
对于本地数据报 socket,其 socket 类型是 AF_LOCAL 和 SOCK_DGRAM。
本地字节流 socket 和 本地数据报 socket 在 bind 的时候,不像 TCP 和 UDP 要绑定 IP 地址和端口,而是绑定一个本地文件,这也就是它们之间的最大区别。
多线程冲突
由于多线程执行操作共享变量的这段代码可能会导致竞争状态,因此我们将此段代码称为临界区(critical section),它是访问共享资源的代码片段,一定不能给多线程同时执行。
我们希望这段代码是互斥(mutualexclusion)的,也就说保证一个线程在临界区执行时,其他线程应该被阻止进入临界区
所谓同步,就是并发进程/线程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步。
同步就好比:「操作 A 应在操作 B 之前执行」,「操作 C 必须在操作 A 和操作 B 都完成之后才能执行」等;
互斥就好比:「操作 A 和操作 B 不能在同一时刻执行」
为了实现进程/线程间正确的协作,操作系统必须提供实现进程协作的措施和方法,主要的方法有两种:
锁:加锁、解锁操作;
信号量:P、V 操作;
而信号量比锁的功能更强一些,它还可以方便地实现进程/线程同步
根据锁的实现不同,可以分为「忙等待锁」和「无忙等待锁」。
现代 CPU 体系结构提供的特殊原子操作指令 —— 测试和置位(Test-and-Set)指令。
原子操作就是要么全部执行,要么都不执行,不能出现执行到一半的中间状态
自旋锁(spin lock)(忙等待锁)
当获取不到锁时,线程就会一直 while 循环,不做任何事情
在单处理器上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
无等待锁
既然不想自旋,那当没获取到锁的时候,就把当前线程放入到锁的等待队列,然后执行调度程序,把 CPU 让给其他线程执行。
避免死锁
如果你想排查你的 Java 程序是否死锁,则可以使用 jstack 工具,它是 jdk 自带的线程堆栈分析工具。
C 写的代码,在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题。
pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 ``pstack
在定位死锁问题时,我们可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。
// gdb 命令
$ gdb -p 87746
// 打印所有的线程信息
(gdb) info thread
3 Thread 0x7f60a610a700 (LWP 87747) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0
2 Thread 0x7f60a5709700 (LWP 87748) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0
* 1 Thread 0x7f60a610c700 (LWP 87746) 0x0000003720e080e5 in pthread_join () from /lib64/libpthread.so.0
//最左边的 * 表示 gdb 锁定的线程,切换到第二个线程去查看
// 切换到第2个线程
(gdb) thread 2
[Switching to thread 2 (Thread 0x7f60a5709700 (LWP 87748))]#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0
// bt 可以打印函数堆栈,却无法看到函数参数,跟 pstack 命令一样
(gdb) bt
#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0
#1 0x0000003720e093ca in _L_lock_829 () from /lib64/libpthread.so.0
#2 0x0000003720e09298 in pthread_mutex_lock () from /lib64/libpthread.so.0
#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:25
#4 0x0000003720e07893 in start_thread () from /lib64/libpthread.so.0
#5 0x00000037206f4bfd in clone () from /lib64/libc.so.6
// 打印第三帧信息,每次函数调用都会有压栈的过程,而 frame 则记录栈中的帧信息
(gdb) frame 3
#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:25
27 printf("thread B waiting get ResourceA \n");
28 pthread_mutex_lock(&mutex_A);
// 打印mutex_A的值 , __owner表示gdb中标示线程的值,即LWP
(gdb) p mutex_A
$1 = {__data = {__lock = 2, __count = 0, __owner = 87747, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}},
__size = "\002\000\000\000\000\000\000\000\303V\001\000\001", '\000' <repeats 26 times>, __align = 2}
// 打印mutex_B的值 , __owner表示gdb中标示线程的值,即LWP
(gdb) p mutex_B
$2 = {__data = {__lock = 2, __count = 0, __owner = 87748, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}},
__size = "\002\000\000\000\000\000\000\000\304V\001\000\001", '\000' <repeats 26 times>, __align = 2}
产生死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。
那么避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。
悲观锁、乐观锁
「互斥锁、自旋锁、读写锁、乐观锁、悲观锁」的选择和使用
互斥锁、自旋锁
互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。
两次线程上下文切换的成本:运行->睡眠,睡眠->就绪
如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap),在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
CAS 函数就把这两个步骤合并成一条硬件级指令,形成原子指令,这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用 while 循环等待实现,不过最好是使用 CPU 提供的 PAUSE 指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
读写锁
读写锁适用于能明确区分读操作和写操作的场景。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
乐观锁与悲观锁
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
乐观锁全程并没有加锁,所以它也叫无锁编程。
只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
一个进程最多可以创建多少个线程?
ulimit -a 命令,查看stack size进程创建线程时默认分配的栈空间大小
ulimit -s 512调整创建线程时分配的栈空间大小为 512k
32 位系统,用户态的虚拟空间只有 3G,如果创建线程时分配的栈空间是 10M,那么一个进程最多只能创建 300 个左右的线程。
比如下面这三个内核参数的大小,都会影响创建线程的上限:
/proc/sys/kernel/threads-max,表示系统支持的最大线程数,默认值是 14553;
/proc/sys/kernel/pid_max,表示系统全局的 PID 号数值的限制,每一个进程或线程都有 ID,ID 的值超过这个数,进程或线程就会创建失败,默认值是 32768;
/proc/sys/vm/max_map_count,表示限制一个进程可以拥有的VMA(虚拟内存区域)的数量,具体什么意思我也没搞清楚,反正如果它的值很小,也会导致创建线程失败,默认值是 65530。
64 位系统,用户态的虚拟空间大到有 128T,理论上不会受虚拟内存大小的限制,而会受系统的参数或性能限制。
线程崩溃了,进程也会崩溃吗?
为什么 C/C++ 语言里,线程崩溃后,进程也会崩溃,而 Java 语言里却不会呢?
- 针对只读内存写入数据
- 访问了进程没有权限访问的地址空间(比如内核空间)
- 访问了不存在的内存,比如NULL
以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
其背后的机制如下:
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
- 注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
调度算法
进程调度/页面置换/磁盘调度算法
进程调度
什么时候会发生 CPU 调度呢?通常有以下情况:
当进程从运行状态转到等待状态;
当进程从运行状态转到就绪状态;
当进程从等待状态转到就绪状态;
当进程从运行状态转到终止状态;
其中发生在 1 和 4 两种情况下的调度称为「非抢占式调度」,2 和 3 两种情况下发生的调度称为「抢占式调度」。
常见的调度算法:
- 先来先服务调度算法
- 最短作业优先调度算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 最高优先级调度算法
- 多级反馈队列调度算法
页面置换
常见的页面置换算法有如下几种:
- 最佳页面置换算法(OPT)
最佳页面置换算法基本思路是,置换在「未来」最长时间不访问的页面。 - 先进先出置换算法(FIFO)
- 最近最久未使用的置换算法(LRU)
- 时钟页面置换算法(Lock)
时钟页面置换算法就可以两者兼得,它跟 LRU 近似,又是对 FIFO 的一种改进。
该算法的思路是,把所有的页面都保存在一个类似钟面的「环形链表」中,一个表针指向最老的页面。
当发生缺页中断时,算法首先检查表针指向的页面:
如果它的访问位位是 0 就淘汰该页面,并把新的页面插入这个位置,然后把表针前移一个位置;
如果访问位是 1 就清除访问位,并把表针前移一个位置,重复这个过程直到找到了一个访问位为 0 的页面为止; - 最不常用置换算法(LFU)
磁盘调度
- 常见的磁盘调度算法有:
- 先来先服务算法
- 最短寻道时间优先算法
可能存在某些请求的饥饿,原因是磁头在一小块区域来回移动。 - 扫描算法
磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向。
扫描调度算法性能较好,不会产生饥饿现象,但是存在这样的问题,中间部分的磁道会比较占便宜,中间部分相比其他部分响应的频率会比较多,也就是说每个磁道的响应频率存在差异。 - 循环扫描算法
只有磁头朝某个特定方向移动时,才处理磁道访问请求,而返回时直接快速移动至最靠边缘的磁道,也就是复位磁头,这个过程是很快的,并且返回中途不处理任何请求,该算法的特点,就是磁道只响应一个方向上的请求。
循环扫描算法相比于扫描算法,对于各个位置磁道响应频率相对比较平均。 - LOOK 与 C-LOOK 算法
那针对 SCAN 算法的优化则叫 LOOK 算法,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
而针 C-SCAN 算法的优化则叫 C-LOOK,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中不会响应请求。
文件系统
Linux 最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
索引节点,也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
目录项,也就是 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小。Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
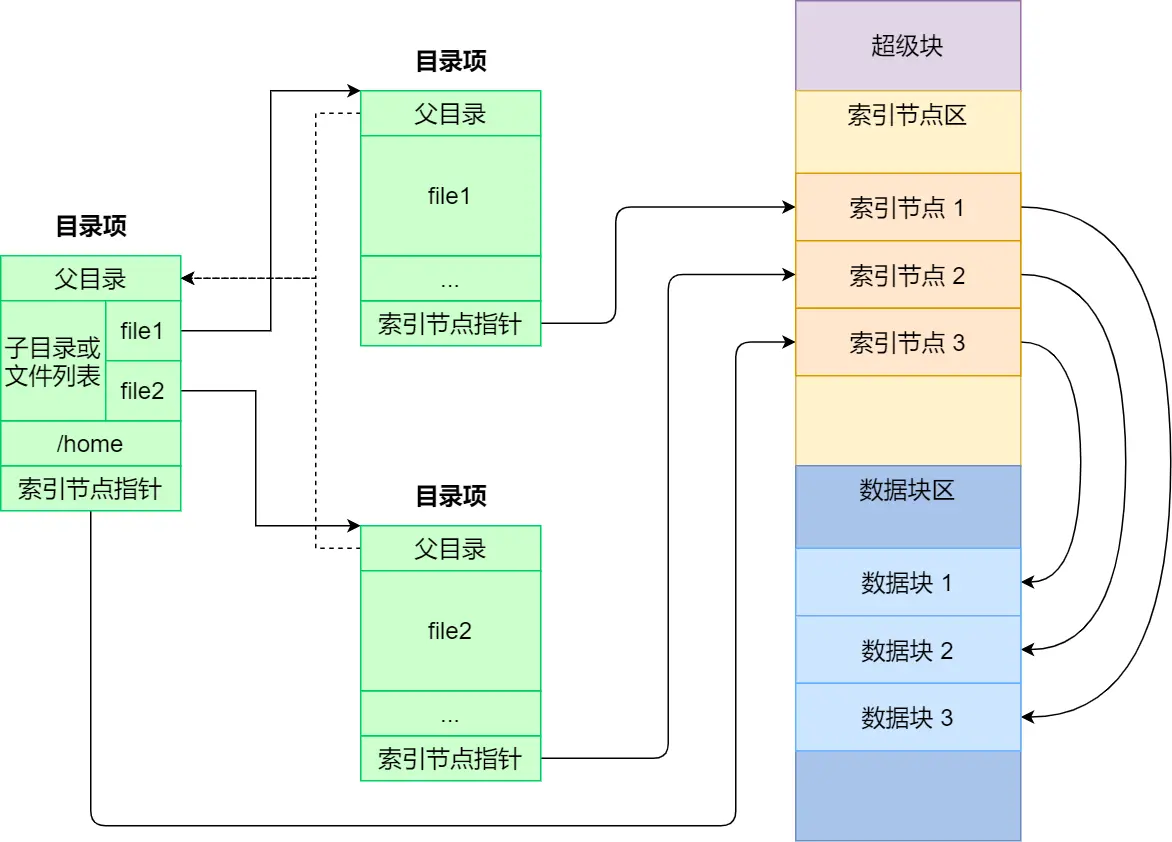
磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
索引节点区,用来存储索引节点;
数据块区,用来存储文件或目录数据;
虚拟文件系统(Virtual File System,VFS)
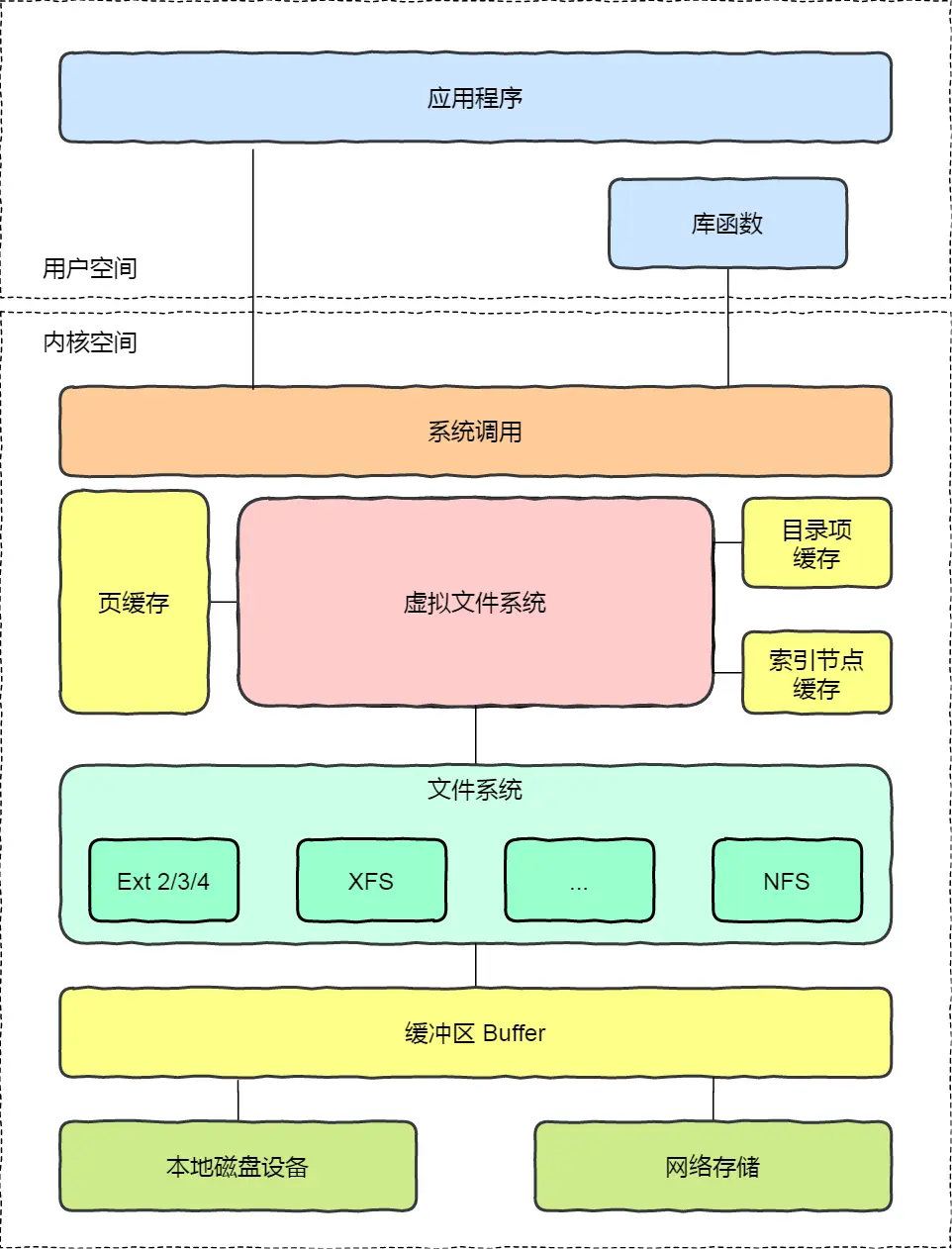
Linux 支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的 /proc 和 /sys 文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。
网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
我们打开了一个文件后,操作系统会跟踪进程打开的所有文件,所谓的跟踪呢,就是操作系统为每个进程维护一个打开文件表,文件表里的每一项代表「文件描述符」,所以说文件描述符是打开文件的标识。
用户和操作系统对文件的读写操作是有差异的,用户习惯以字节的方式读写文件,而操作系统则是以数据块来读写文件,那屏蔽掉这种差异的工作就是文件系统了。
文件的数据是要存储在硬盘上面的,数据在磁盘上的存放方式,就像程序在内存中存放的方式那样,有以下两种:
连续空间存放方式,文件头里需要指定「起始块的位置」和「长度」。有「磁盘空间碎片」和「文件长度不易扩展」的缺陷。
非连续空间存放方式,又可以分为「链表方式」和「索引方式」。
「隐式链表」:文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置。稳定性较差,系统在运行过程中由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失。
「显式链接」:把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
链表 + 索引的组合,这种组合称为「链式索引块」,它的实现方式是在索引数据块留出一个存放下一个索引数据块的指针,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。
索引的方式,这种组合称为「多级索引块」,实现方式是通过一个索引块来存放多个索引数据块。
空闲空间管理:空闲表法,空闲链表法,位图法
空闲表法
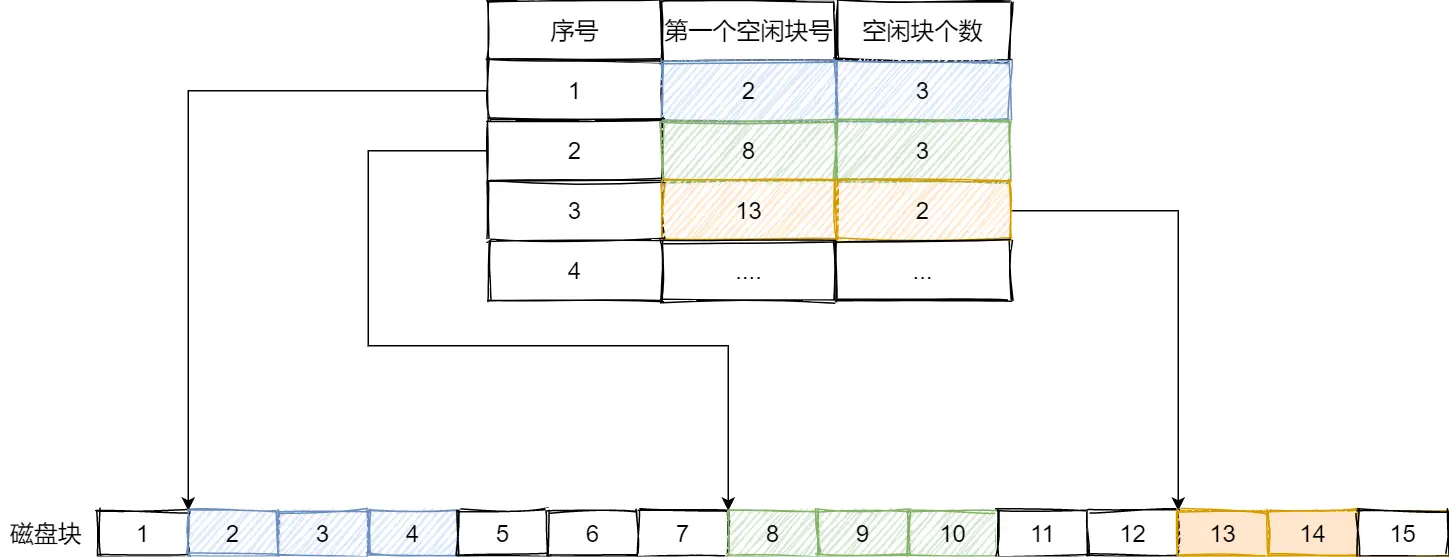
空闲链表法
每一个空闲块里有一个指针指向下一个空闲块
位图法
位图是利用二进制的一位来表示磁盘中一个盘块的使用情况,磁盘上所有的盘块都有一个二进制位与之对应。
当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。
在 Linux 文件系统就采用了位图的方式来管理空闲空间
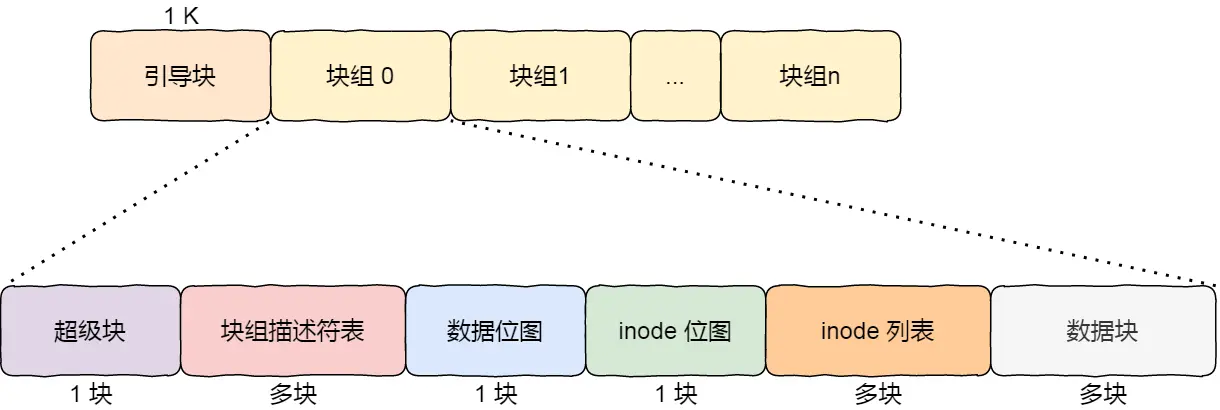
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
超级块,包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等。
块组描述符,包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
数据位图和 inode 位图, 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
inode 列表,包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
数据块,包含文件的有用数据。
你可以会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
软链接和硬链接
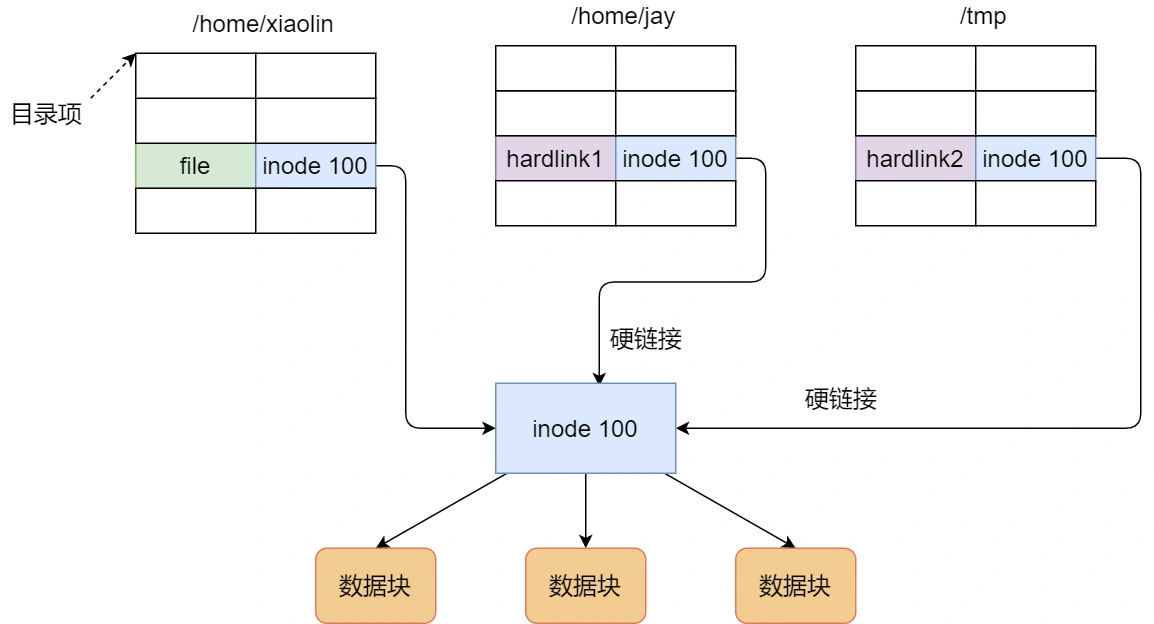
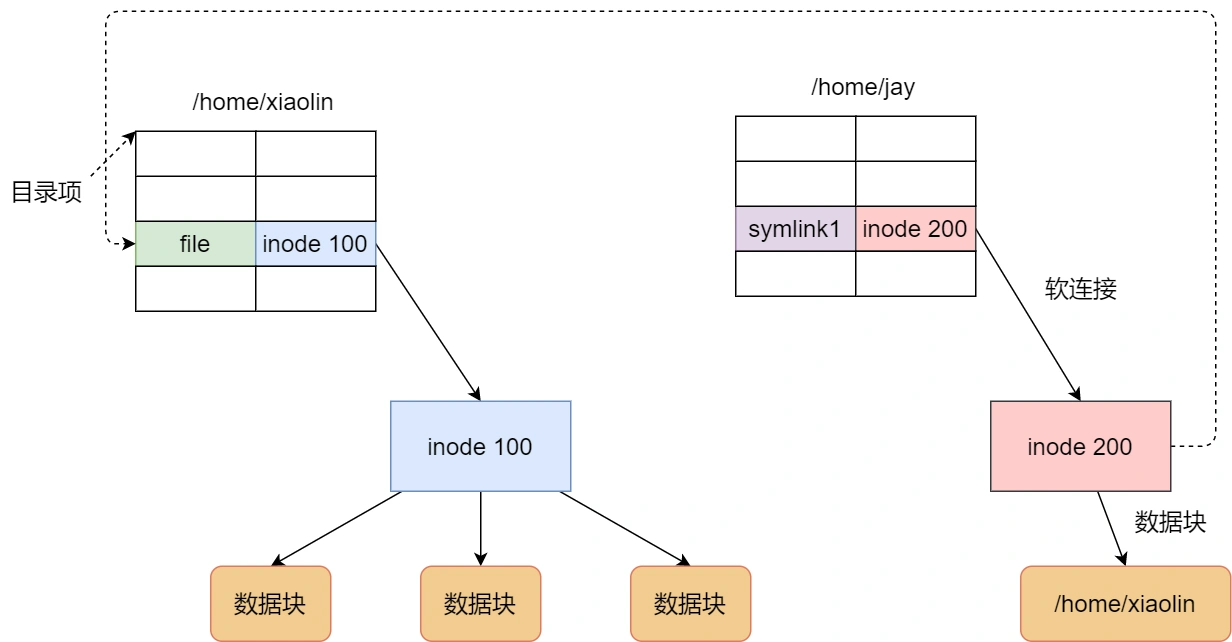
文件的读写方式各有千秋,对于文件的 I/O 分类也非常多,常见的有
缓冲与非缓冲 I/O
直接与非直接 I/O
阻塞与非阻塞 I/O VS 同步与异步 I/O
根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
根据是「否利用操作系统的缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
直接 I/O,不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘。
非直接 I/O,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。
非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。
为了解决这种傻乎乎轮询方式,于是 I/O 多路复用技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
整个流程要比阻塞 IO 要复杂,似乎也更浪费性能。但 I/O 多路复用接口最大的优势在于,用户可以在一个线程内同时处理多个 socket 的 IO 请求。用户可以注册多个 socket,然后不断地调用 I/O 多路复用接口读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
cat /proc/meminfo实时获取系统内存情况
Page Cache = Buffers + Cached + SwapCached
设备管理
键盘敲入 A 字母时,操作系统期间发生了什么?
为了屏蔽设备之间的差异,每个设备都有一个叫设备控制器(Device Control) 的组件,比如硬盘有硬盘控制器、显示器有视频控制器等。
控制器是有三类寄存器,它们分别是状态寄存器(Status Register)、 命令寄存器(Command Register)以及数据寄存器(Data Register)