kernels
1 elementwise
针对不同数据类型和向量化粒度的张量逐元素加法
#define INT4(value) (reinterpret_cast<int4 *>(&(value))[0]) // i32x4
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0]) // f32x4
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0]) // f16x2, f16x8
#define BFLOAT2(value) (reinterpret_cast<__nv_bfloat162 *>(&(value))[0])
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0]) // f16x8_pack
对于FLOAT4(value)这个宏,FLOAT4(c[idx]) -> (reinterpret_cast<float4 *>(&(c[idx]))[0])
c[idx]: 是 float* c 中第 idx 个 float 元素。
&c[idx]: 取这个 float 的地址,得到 float*。
reinterpret_cast<float4*>(…): 把这个 float* 强制转换为 float4*。
[0]: 对这个指针取第一个元素(即它自己指向的内容),结果是 float4&(引用)
#pragma unroll
for (int i = 0; i < 8; i += 2) {
// __hmax2 for half2 x 4
HALF2(pack_y[i]) = __hmax2(HALF2(pack_x[i]), z2);
}
能在编译时展开
2 histogram
直方图(histogram)统计功能
int atomicAdd(int* address, int val);
问题:INT4(a[idx])是否要求数组a元素个数为4倍数?
3 sigmoid
y=1/(1+exp(-x))
// 避免结果溢出设置的数字
#define MAX_EXP_F32 88.3762626647949f
#define MIN_EXP_F32 -88.3762626647949f
#define MAX_EXP_F16 __float2half(11.089866488461016f)
#define MIN_EXP_F16 __float2half(-9.704060527839234f)
// fminf:返回两个 float 类型参数中的较小值。如果其中一个参数是 NaN(非数值),则返回另一个参数
v = fminf(fmaxf(v, MIN_EXP_F32), MAX_EXP_F32);
// half,half2相关函数
__hmin(__hmax(v, MIN_EXP_F16), MAX_EXP_F16);
4 relu
y=max(0,x)
5 elu
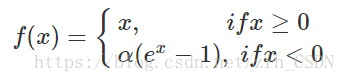
__device__ __forceinline__ float elu(float x) {
return x > 0.f ? x : ALPHA * (expf(x) - 1.f);
}
__forceinline__的作用 :
它会覆盖编译器的默认优化策略 (如成本收益分析,ROI),强制要求编译器对函数进行内联,即使编译器认为内联可能不划算(例如函数体较大)
。
尽管称为“强制”,但最终是否内联仍取决于编译器实现。例如,某些复杂或递归函数可能无法被内联
6 gelu
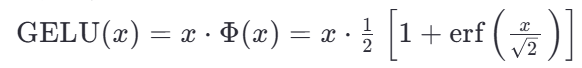
float tanhf(float x);
float erff(float x);
__device__ half hexp(half x);
7 swish
y=x*sigmoid(x) = x/(1+exp(-x))
__device__ __forceinline__ half swish_half(half x) {
return __hmul(x, __hdiv(__float2half(1.0f),
__hadd(__float2half(1.0f), hexp(__hneg(x)))));
}
8 hardswish
__device__ __forceinline__ float hardswish(float x) {
if (x >= THRESHOLD_A) {
return x;
} else if (x <= THRESHOLD_B) {
return 0;
} else {
return x * (x + 3) / 6;
}
}
9 hardshrink
__device__ __forceinline__ float hardshrink(float x) {
if (x > LAMBD || x < -LAMBD) {
return x;
} else {
return 0;
}
}
10 embedding
__global__ void embedding_f32_kernel(const int *idx, float *weight,
float *output, int n, int emb_size) {
int tx = threadIdx.x;
int bx = blockIdx.x;
int tid = bx * blockDim.x + tx;
int offset = idx[bx] * emb_size; // 每个 block 处理一个样本
output[bx * emb_size + tx] = weight[offset + tx];
}