https://zhuanlan.zhihu.com/p/685020608
https://hebiao064.github.io/fa3-attn-backend-basic
https://zhuanlan.zhihu.com/p/17533058076
https://blog.csdn.net/v_JULY_v/article/details/133619540
https://zhuanlan.zhihu.com/p/639228219
v1
https://arxiv.org/abs/2205.14135
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
自注意力模块在序列长度上具有二次方的时间和内存复杂度。这导致在处理长序列时速度变慢且内存需求巨大

v2
https://arxiv.org/abs/2307.08691
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
GPU对不同thread blocks和warps工作分配不是最优的,造成了利用率低和不必要的共享内存读写。
- 减少non-matmul FLOPs-最后算softmax的分母
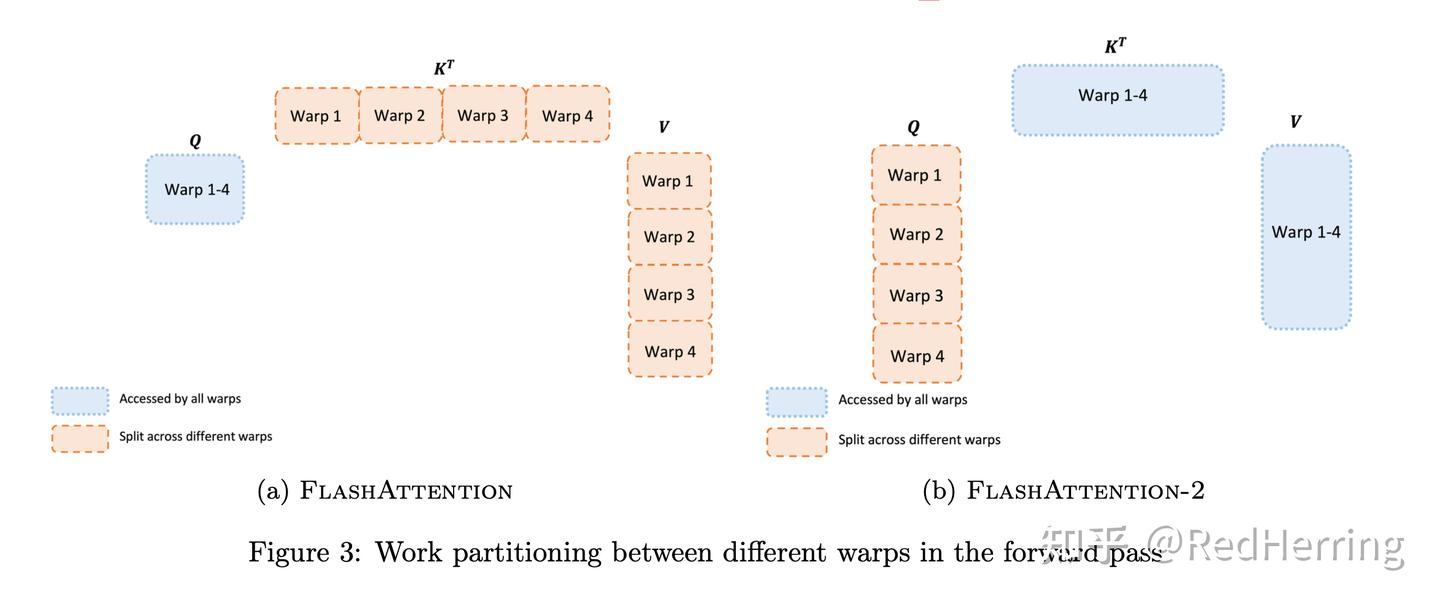
- 在序列长度这一维度上进行并行化,FlashAttention-2将 Q 移到了外循环 i,K V 移到了内循环 j,由于改进了算法使得warps之间不再需要相互通信去处理,所以外循环可以放在不同的thread block上(之前只在batch和heads两个维度上进行了并行化,使用一个thread block来处理一个attention head,总共需要thread block的数量等于batch size × number of heads)
- 在一个attention计算块内,将工作分配在一个thread block的不同warp上

v3
https://arxiv.org/abs/2407.08608
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FA2 算子在 H100 上的利用率不高。H100 新增了 TMA 硬件 Warpgroup 级别的 GEMM 指令,是 NV 首个可实现完全异步通信和计算的 GPU,同时具有 FP8 低精度运算的能力。
Hopper 架构新指令:
- WGMMA operand A 可以从 RMEM/SMEM 读取,operand B 只能从 SMEM 读取。
- TMA,允许程序在 GMEM 和 SMEM 之间异步且双向地传输 1D 到 5D 的张量。TMA 不仅可以将相同的数据传输到调用 SM 的 SMEM,还可以传输到同一 Thread Block Cluster 中的其他 SM 的 SMEM。这被称为 multicast
方案:
- A100 之前的异步:warp 间异步,Warp Specialization。A100 的异步:同一 warp 中,Multistage。H100 的异步:Warp Specialization + Intra-warpgroup overlapping。
- FP8 低精度运算
Flash-Decoding
https://crfm.stanford.edu/2023/10/12/flashdecoding.html
Flash-Decoding for long-context inference
需要增强处理长上下文能力。attention操作对内存的访问会随着batch size增加而增加,而模型中其他操作只和模型大小相关。
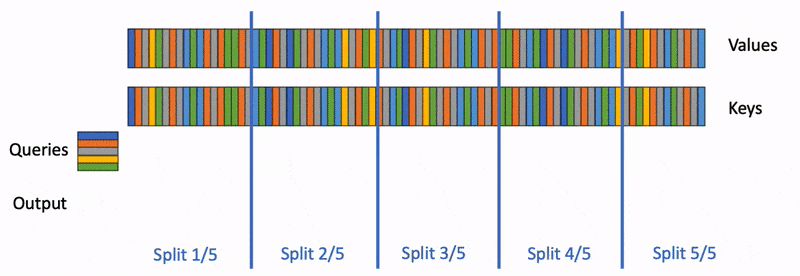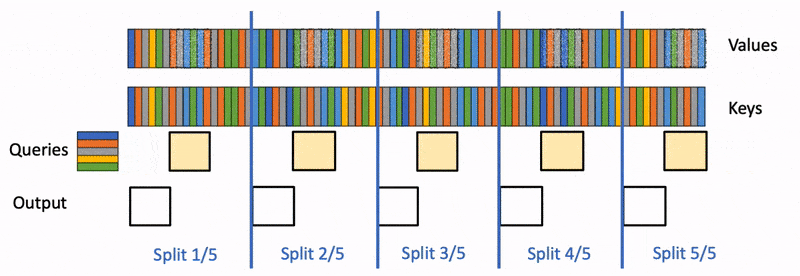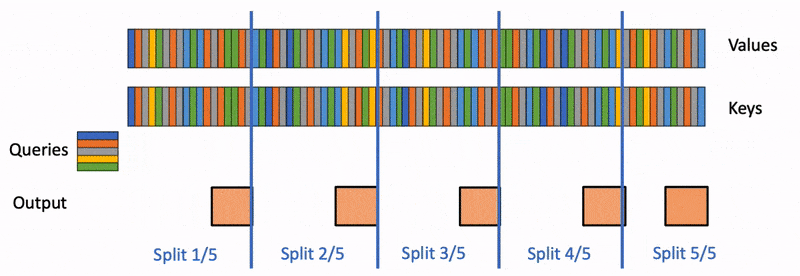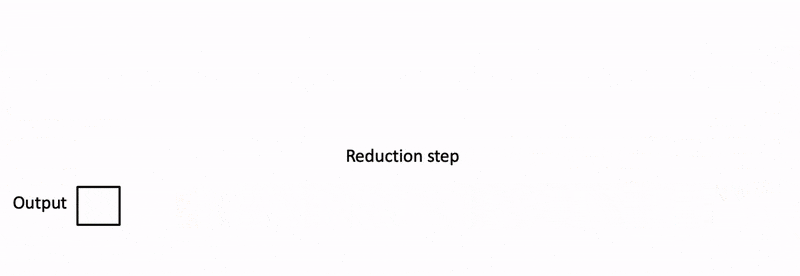
增加了一个新的并行化维度:keys/values的序列长度。
FlashDecoding++
https://arxiv.org/abs/2311.01282
FlashDecoding++: Faster Large Language Model Inference on GPUs
- 同步partial softmax更新
- Flat GEMM操作的计算资源未得到充分利用。当batch size较小时,cublas和cutlass会将矩阵填充zeros以执行更大batchsize的GEMM,导致计算利用率不足50%。
- 动态输入和固定硬件配置影响了LLM推理的性能。例如,当batch size较小时,LLM推理的解码过程是memory-bounded,而当batch size较大时是compute-bounded。
解决方案:
- 为分块softmax计算设置了一个共享的最大值
- 只将矩阵大小填充到8 + 双缓冲等技术
- 动态kernel优化