vscode + wsl + docker / conda
docker
- 在wsl2中安装docker
- 要以非root身份管理docker:
https://docs.docker.com/engine/install/linux-postinstall/ - 搭建CUDA & CUDNN 开发环境:
https://zhuanlan.zhihu.com/p/408403790
https://zhuanlan.zhihu.com/p/580156606
docker pull nvidia/cuda:12.6.3-cudnn-devel-ubuntu22.04
docker run -itd -v ~/work:/work --name=Ubuntu22.04-CUDA --gpus all nvidia/cuda:12.6.3-cudnn-devel-ubuntu22.04
docker ps
docker exec -it Ubuntu22.04-CUDA /bin/bash
nvidia-smi
nvcc -V
- 在vscode中连接docker。打开命令面板,选择Attach to Running Container,选择容器。
- 之前的命令中~/work:/work是将主机上的 ~/work 文件夹挂载到容器中的 /work 文件夹,因此在/work中编写代码即可。
- 测试运行,使用 NVIDIA 提供的 CUDA 示例
git clone https://github.com/NVIDIA/cuda-samples.git
cd cuda-samples/Samples/0_Introduction/vectorAdd
mkdir build
cd build
cmake ..
报错:

查看当前工具链支持的架构:
nvcc --list-gpu-arch

CMakeLists.txt中的set(CMAKE_CUDA_ARCHITECTURES 50 52 60 61 70 72 75 80 86 87 89 90 100 101 120)删掉工具链不支持的架构
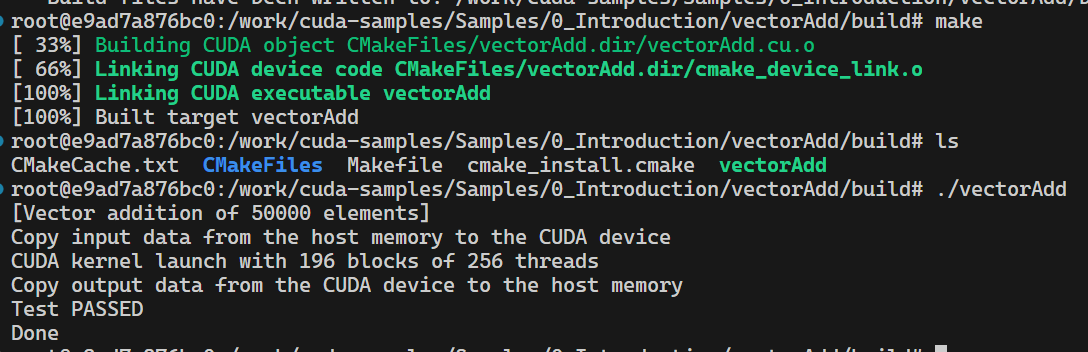
CUDA 的编译和链接机制会将不同架构的代码打包到同一个二进制文件中。CUDA 编译器(nvcc)允许你为目标 GPU 指定多个架构(如 50, 60, 86 等),并为每个架构生成相应的代码。修改后的设置中,虽然包含了一些超出 RTX 3080 支持范围的架构(如 90),但 nvcc 并不会因为这些架构的存在而报错。它会尝试为所有指定的架构生成代码,即使某些架构可能无法在当前硬件上运行。

CUDA、CUDA toolkit、CUDNN、NVCC关系
https://blog.csdn.net/qq_41094058/article/details/116207333nvidia-smi输出及使用
https://blog.csdn.net/u014636245/article/details/83933834在vscode中调试cuda代码
http://fancyerii.github.io/2024/01/17/vscode-cuda-debug/
conda
虚拟环境中完成cs149gpt
(先在docker容器中尝试)在venv中
apt install python3-venv python3-pip build-essential
python3 -m venv cs149-env
source cs149-env/bin/activate
pip install numpy torch
deactivate
rm -rf cs149-env
报错

相关issue
https://github.com/stanford-cs149/cs149gpt/issues/2
我的环境:
Python 3.10.12
torch 2.7.0
Cuda 12.6
根据此解决方案改用conda。注意"cpuonly"强制 conda 安装 不带 CUDA 支持的 PyTorch
apt update && apt install wget bzip2 -y
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p /root/miniconda3
export PATH="/root/miniconda3/bin:$PATH"
conda create -n gpt149 python=3.10
conda init bash
source ~/.bashrc
conda activate gpt149
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 cpuonly python=3.10 numpy=1.26 ninja tiktoken -c pytorch -c conda-forge
显示"No CUDA runtime is found",但是能正常运行。
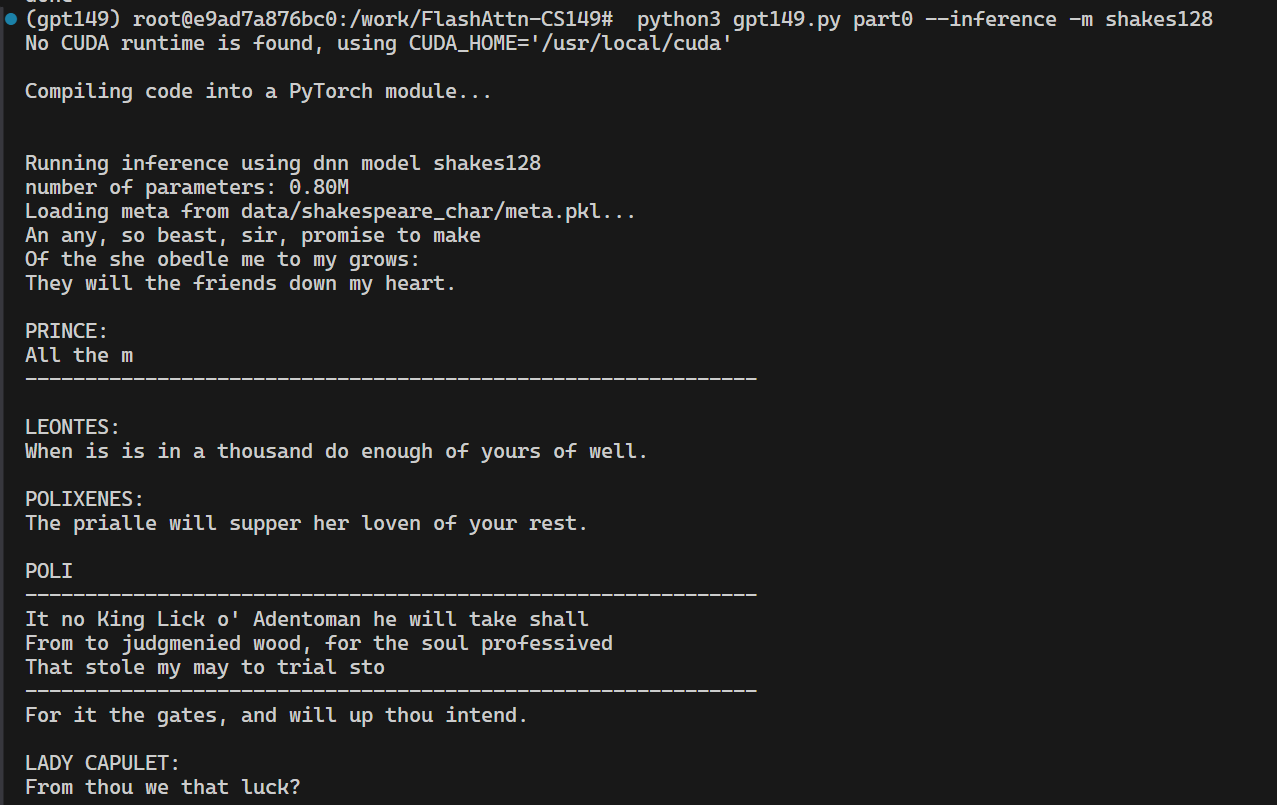
进一步地,尝试取消cpuonly,pytorch-cuda指定为11.8(工具链支持到12.6但是报错发生冲突,因此改为11.8)
pip uninstall torch torchvision torchaudio
pip3 install torch==2.1.2+cu118 torchvision==0.16.2+cu118 torchaudio==2.1.2 --extra-index-url https://download.pytorch.org/whl/cu118
检查
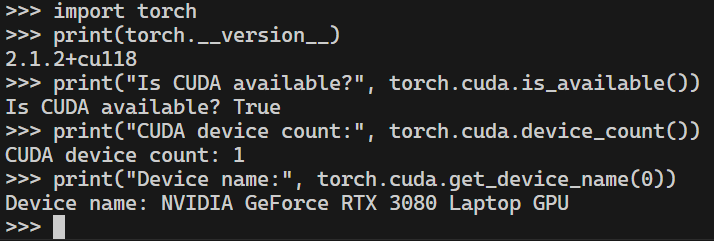
不再显示"No CUDA runtime is found"
同样方法在容器外也能成功。
如果还是找不到:
确认CUDA 运行时库 libcudart 确实存在
ls /usr/local/cuda/lib64/libcudart.so*
updatedb
locate libcudart.so


手动设置:
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
基础知识
https://ai.oldpan.me/t/topic/72
GPU中的基本概念
https://zhuanlan.zhihu.com/p/150810484
硬件资源
SP:streaming processor,也称为CUDA core。
SM:多个SP加上其他的一些资源组成一个streaming multiprocessor,也叫GPU大核。
软件资源
Grid,Block,Warp,Thread
Thread-local memory和resigters
Block-shared memory
Grid之间会有Global memory和Cache
1个Warp = 32 threads
一个thread对应一个SP,SM和Grid无对应关系
CUDA编程模型
Kernel
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
层级
假设线程块和网格都是三维的:
线程块的全局偏移 + 线程块内的线程偏移
int threadId = (blockIdx.z * gridDim.y * gridDim.x + blockIdx.y * gridDim.x + blockIdx.x)
* (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x);
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
__syncthreads()屏障
可选的层次结构Thread Block Clusters(线程块集群),与线程块在流多处理器上保证同时调度一样,集群中的线程块也保证在GPU中的GPU Processing Cluster (GPC)上同时调度
CUDA支持最多8个线程块作为便携式集群大小。
还有两个额外的只读内存空间可供所有线程访问:常量和纹理内存空间。
异构编程
CUDA 编程模型 假设主机(CPU)和设备(GPU)是独立的计算单元,分别拥有自己的内存空间。
传统内存管理 需要显式分配、释放和传输数据,增加了编程复杂性。
统一内存 提供了一种简化的内存模型,将主机和设备的内存空间合并为一个连贯的地址空间,消除了显式数据传输的需求。
统一内存的优点 包括简化编程、提高可移植性和支持超额订阅。
异步SIMT编程模型