简单介绍:
https://cloud.tencent.com/developer/article/2411953
https://blog.csdn.net/qq_43543209/article/details/135659463
https://blog.csdn.net/weixin_42135087/article/details/121174706
https://community.arm.com/management/archive/cn/b/blog/posts/arm-1203521971
开源项目:
https://github.com/caibirda/islet_runable
# 如果下载失败考虑网络问题
git config --global http.proxy http://192.168.101.11:7890
export https_proxy=http://192.168.101.11:7890
export http_proxy=http://192.168.101.11:7890
export all_proxy=socks5://192.168.101.11:7890
aarch64介绍:
https://blog.csdn.net/jimfire/category_11329148.html
sudo apt-get install qemu-user gcc-aarch64-linux-gnu
# .c
aarch64-linux-gnu-gcc -static -o hello hello.c
qemu-aarch64 ./hello
# .s
aarch64-linux-gnu-as -c first.s
aarch64-linux-gnu-gcc -static -o first first.o
# 检查返回值
echo $?
AArch64中有31个通用寄存器x0,x1,…x30,x31寄存器被称为xzr,也就是零寄存器。
为了提供32位的处理,我们可以使用Wn来代替Xn表示32位。
所以x6寄存器的低32位就是w6。也没必要声明高32位。xzr寄存器的32位等价寄存器是wzr。
当一个指令的目的寄存器是32位寄存器,那么高32位置为0。它们是不被保留的。
mov w0, #2 // w0 ← 2
add w0, w1, wzr // w0 ← w1 + 0
orr b0, b1, wzr
add w0, #1, w1 // ERROR: second operand should be an integer register
add w0, #1, #2 // ERROR: second operand should be an integer register.
main函数总是接受程序名为第一个参数。
// test.s
.text
.globl main
main:
add w0, w0, #1 // w0 ← w0 + 1
ret // return from main
$ aarch64-linux-gnu-gcc -c test.s
$ aarch64-linux-gnu-gcc -o test test.o
$ ./test ; echo $?
2
$ ./test foo ; echo $?
3
$ ./test foo bar ; echo $?
4
reg, LSL, #amount
reg, LSR, #amount
reg, ASR, #amount
reg, ROR, #amount
add r1, r2, r3, LSL #4 /* r1 ← r2 + (r3 << 4)
一个扩展操作符以kxtw的形式,其中k是一个整型值,该值是我们想要扩展的宽度。w是窄的哪个值。
对于前者,整型的类型能够使U(unsigned)或者S(signed,例如,补码)。对于后者,宽度能够使B,H或者W,分别对应byte(寄存器的低8位),half-word(寄存器的低16位)或者word(寄存器的低32位)。
这也意味着扩展符有uxtb, sxtb, uxth, sxth, uxtw, sxtw。
add x0, x1, w2, sxtb // x0 ← x1 + ExtendSigned8To64(w2)
add w0, w1, w2, sxtb // w0 ← w1 + ExtendSigned8To32(w2)
add x2, x0, x1, sxtw #1 // x2 ← x0 + (ExtendSigned16To64(x1) << 1)
add x2, x0, x1, sxtw #2 // x2 ← x0 + (ExtendSigned16To64(x1) << 2)
mul Rdest, Rsource1, Rsource2 // Rdest ← Rsource1 * Rsource2
umull Xdest, Wsource1, Wsource2 // Xdest ← Wsource1 * Wsource2
smull Xdest, Wsource1, Wsource2 // Xdest ← Wsource1 * Wsource2
mul Xlower, Xsource1, Xsource2 // Xlower ← Lower64Bits(Xsource1 * Xsource2)
smulh Xupper, Xsource1, Xsource2 // Xupper ← Upper64Bits(Xsource1 * Xsource2)
udiv Rdest, Rsource1, Rsource2 // Rdest ← Rsource1 / Rsource2
sdiv Rdest, Rsource1, Rsource2 // Rdest ← Rsource1 / Rsource2
mvn Rdest, Rsource // Rdest ← ~Rsource
// and,orr和eor
and Rdest, Rsource1, #immediate // Rdest ← Rsource1 & immediate
and Rdest, Rsource1, Rsource2 // Rdest ← Rsource1 & Rsource2
and Xdest, Xsource1, Xsource2, shiftop // Xdest ← Xsource1 & shiftop(Xsource2)
and Wdest, Wsource1, Wsource2, shiftop // Wdest ← Wsource1 & shiftop(Wsource2)
// bic(位清空),orn(或非)和eon(异或非)
orn Rdest, Rsource1, Rsource2 // Rdest ← Rsource1 | ~Rsource2
orn Xdest, Xsource1, Xsource2, shiftop // Xdest ← Xsource1 | ~shiftop(Xsource2)
orn Wdest, Wsource1, Wsource2, shiftop // Wdest ← Wsource1 | ~shiftop(Wsource2)
ldr W2, [X1] // W2 ← *X1 (32-bit load)
ldr X2, [X1] // X2 ← *X1 (64-bit load)
ldr W2, [X1, #4] // W2 ← *(X1 + 4) [32-bit load]
ldr W2, [X1, #-4] // W2 ← *(X1 - 4) [32-bit load]
ldr X2, [X1, #240] // X2 ← *(X1 + 240) [64-bit load]
ldr X2, [X1, #400] // X2 ← *(X1 + 400) [64-bit load]
// ldr X2, [X1, #404] // Invalid offset, not multiple of 8!
// ldr X2, [X1, #-400] // Invalid offset, must be positive!
// ldr X2, [X1, #32768] // Invalid offset, out of the range!
ldr W1, [X2, X3] // W1 ← *(X2 + X3) [32-bit load]
ldr X1, [X2, X3] // X1 ← *(X2 + X3) [64-bit load]
ldr W1, [X2, W3, sxtw] // W1 ← *(X2 + ExtendSigned32To64(W3)) [32-bit load]
ldr W1, [X2, W3, uxtw] // W1 ← *(X2 + ExtendUnsigned32To64(W3)) [64-bit load]
ldr W1, [X2, W3, sxtw #3] // W1 ← *(X2 + ExtendSigned32To64(W3 << 3)) [32-bit-load]
在AArch64中有2中索引模式:预先索引(pre-indexing)和事后索引(post-indexing)模式。在预先索引模式下,其基地址寄存器添加偏移计算地址,并且这个地址会写回基地址寄存器。在事后索引模式中,基地址被用于计算地址,但是在地址访问基地址寄存器后会更新地址的值,该值是添加了偏移的。
这两种方式看起来有点相似,都是更新用偏移基地址寄存器。它们不同之处在于偏移的计算时机:预先索引模式会在访问地址之前计算,事后索引模式会在访问之后计算。而我们能够使用的偏移值必须在-256到255之间。
ldr X1, [X2, #4]! // X1 ← *(X2 + 4)
// X2 ← X2 + 4
ldr X1, [X2], #4 // X1 ← *X2
// X2 ← X2 + 4
ldr Xn, addr_of_var // Xn ← &var
// ldr Wn, addr_of_var // Wn ← &var
...
addr_of_var : .dword variable // This tells the assembler that
// we want here the address of var
// (This is not to be executed!)
...
ldr Xm, [Xn] // Xm ← *Xn [64-bit load]
ldr Wm, [Xn] // Wm ← *Xn [32-bit load]
全局变量被定义在.data节。为了实现这个方法,我们只要简单地定义它们的初始值。如果我们想定义一个32位的变量,我们使用.word。如果我们想顶一个64位的变量,我们使用.dword。
在Linux中AArch64不需要内存访问对其。但是如果它们对齐了,则它们在硬件中会执行得快一点。所以我们使用.balign指令去按照数据得尺寸(以字节)对齐每个变量。
// globalvar.s
.data
.balign 8 // Align to 8 bytes
.byte 1
global_var64 : .dword 0x1234 // a 64-bit value of 0x1234
// alternatively: .word 0x1234, 0x0
.balign 4 // Align to 4 bytes
.byte 1
global_var32 : .word 0x5678 // a 32-bit value of 0
注意,有必要在最后的连接阶段使用-static标记。这将创建一个static文件,这个文件被直接加载到内存。默认地,程序运行的时候,链接器是创建动态文件,这些动态文件被动态链接器加载。动态链接器会在一个地址上加载程序,超过232个提交这些地址非法。当使用.dword,静态链接器保证了对动态链接器的声明是发射的,所以后者能够在运行时修复64位地址。
GDB调试
$ qemu-arm -g 12345 ./a.out &
$ gdb-multiarch ./a.out
(gdb) set arch arm
The target architecture is assumed to be mips
(gdb) set endian little
The target is assumed to be little endian
(gdb) target remote localhost:12345
Remote debugging using localhost:12345
0x00400280 in _ftext ()
(gdb) x/i $pc
=> 0x767cb880 move $t9, $ra
show architecture 和 show endian 检查当前设置。 可使用专为 ARM 设计的 GDB 版本,如 arm-none-eabi-gdb。
// 无条件分支
/* branch */
.text
.globl main
main:
mov w0, #3 // w0 ← 3
b jump // branch to label jump
mov w0, #4 // w0 ← 4
jump:
ret // end function
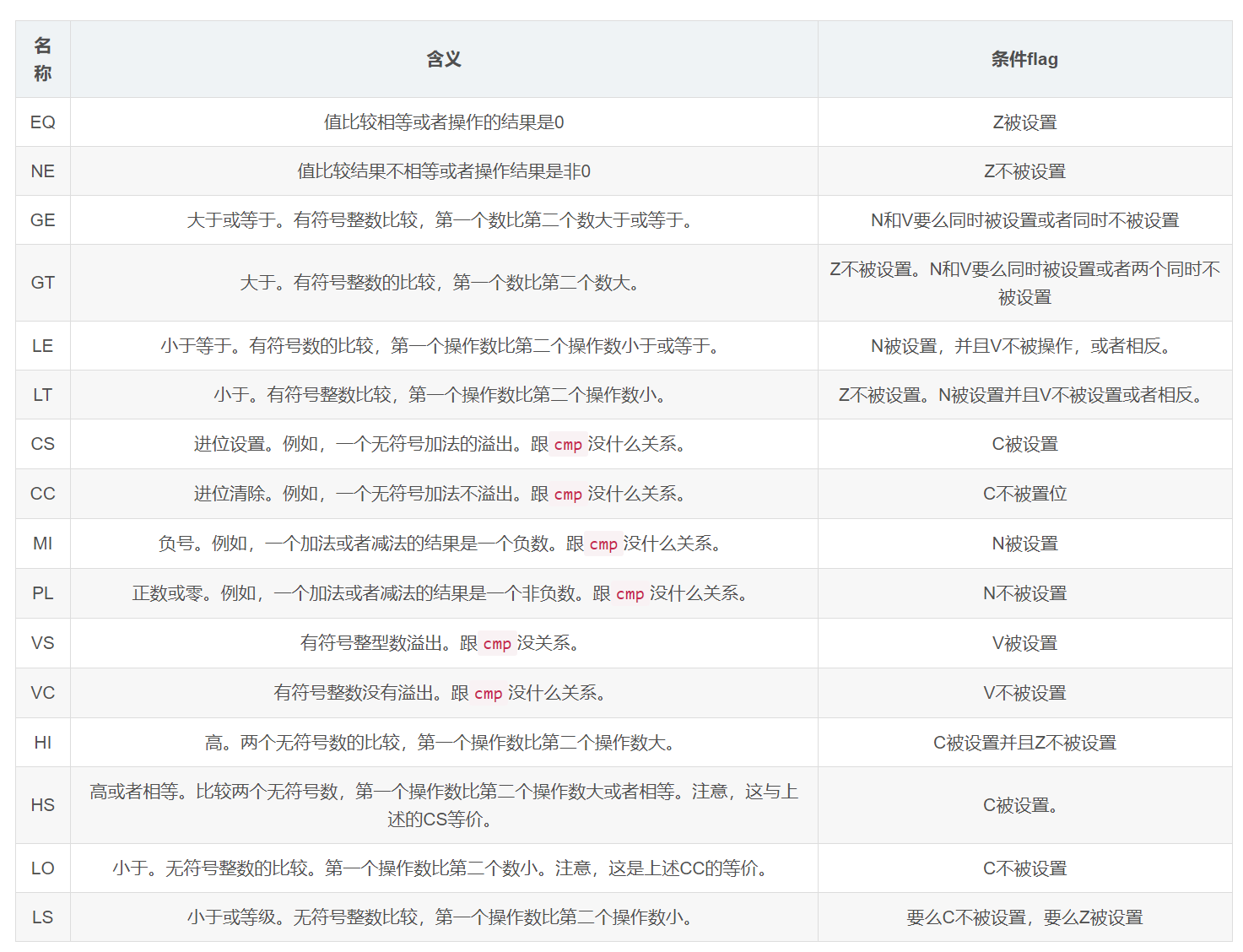
条件分支指令: b.cond
该指令在它的操作数上面有一点特殊,就是条件码,它是以指令名称的形式体现的。这个cond部分就是条件码,并且必须是上面所述的一部分。
b.lt label1 // if w0 < 0 then branch to label1
b.eq label2 // if w0 == 0 then branch to label2
b.gt label3 // if w0 > 1 then branch to label3
label1:
// code for label1
b end_of_arithmetic_if // branch to end_of_arithmetic_if
label2:
// code for label2
b end_of_arithmetic_if // branch to end_of_arithmetic_if
label3:
// code for label3
b end_of_arithmetic_if // branch to end_of_arithmetic_if
end_of_arithmetic_if:
// rest ouf our Fortran program :)
调用一个函数的核心是跳转分支,但是这是一个特殊的常用分支,因此,有必要为此单独设置一个指令。在AArch64中,这个指令就是bl,其意思是branch和link。它是一个无条件分支,该分支的作用是设置x30寄存器中的值是下一条指令的地址。回忆一下,x30是一个通用目的寄存器,但是在本例中,我们给予它特殊的意义:它包含了函数结束之后的地址。历史原因,当x30寄存器被用于此目的时,它被称为链接寄存器。
从函数返回后,唯一我们叫做的事情就是跳转到x30寄存器中的的地址。有一个指令能够无条件跳转到保存在寄存器中的地址,叫br。所以,调用一个函数和返回一个函数的过程如下。
.text
my_function:
br x30
caller:
bl my_function
// more instructions ...
但是从一个函数返回是一个通用操作,所以,我们直接用ret,而不用br x30。
.text
my_function:
ret
caller:
bl my_function
// more instructions ...
x0-x7被用来传递参数和返回值。这些寄存器的值可能会被调用函数自由修改(callee)所以调用者会忽略它们中的内容。即使它们不被用来传递参数和返回值。这也意味着它们在实际应用中是调用者保存寄存器。
x8-x18是对每个函数而言是临时寄存器。对于函数而言,它不管它们里面的值,因此,在实际过程中,它们是调用者保存寄存器。
x19-x28寄存器是被调用者保存寄存器,即它们被函数调用之前应保存,在返回之后应该恢复
我们已经知道x30是链接寄存器并且它的值必须被保存直到函数使用ret指令返回到调用者。
.data
.balign 8
/* This is the greeting message */
say_hello: .asciz "Hello world!"
.balign 8
/* We need to keep x30 otherwise we will not be able to return from main! */
keep_x30: .dword 0
.text
/* We are going to call a C-library puts function */
.globl puts
.globl main
main:
ldr x0, addr_keep_x30 // w0 ← &keep_30 [64]
str x30, [x0] // *keep_30 ← x30 [64]
ldr x0, addr_say_hello // w0 ← &say_hello [64]
bl puts // call puts
ldr x0, addr_keep_x30 // w0 ← &keep_30 [64]
ldr x30, [x0] // x30 ← *keep_30 [64]
mov w0, #0 // w0 ← 0
ret // return
addr_keep_x30 : .dword keep_x30
addr_say_hello: .dword say_hello