https://novel.ict.ac.cn/aics/llmytk/llm-kcjj/
数据准备
- tokenization
- embedding:one-hot, word2vec(CBOW通过上下文预测目标词, Skip-gram目标词来预测其上下文)
- position encoding(三角函数,BERT中的可学习的位置嵌入,RoPE)
模型结构
- seq2seq(RNN或LSTM固定长度、权重相同)
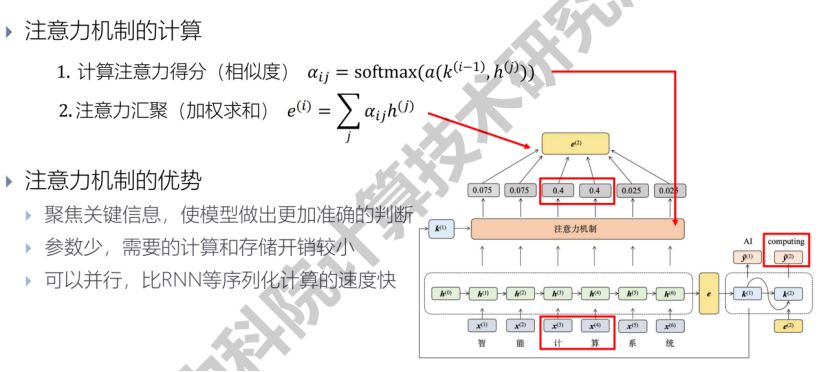
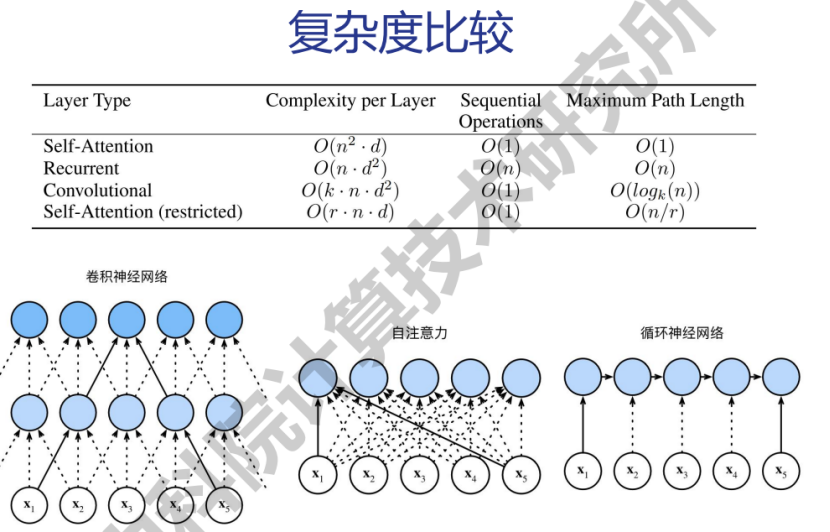
- attention:scaled dot-product attention, self-attention, multi-head attention
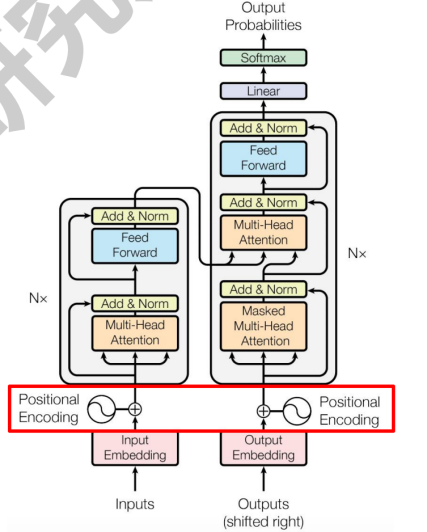
- Transformer
- 编码器输入:one-hot与embedding矩阵相乘/查询 + 三角函数
- 编码器:N x ((QKV分别线性层得到 -> 缩放点积注意力 -> 拼接、线性层) -> (残差连接 -> 层归一化) -> (FFN前馈层512-2048-512) -> (残差连接 -> 层归一化))
- 解码器输入:右移一位
- 解码器:N x ((掩码多头自注意力,QKV来自decoder) -> (残差连接 -> 层归一化) -> (多头交叉注意力,Q来自decoder,KV来自encoder) -> (残差连接 -> 层归一化) -> (FFN前馈层512-2048-512) -> (残差连接 -> 层归一化))
- Transformer的输出: Linear将输出向量映射为词元数字索引的概率 -> softmax和groundtruth计算交叉熵损失
- Transformer的训练: Adam(adaptive moment estimation,自适应矩估计),warmup
- encoder-decoder(T5)
- encoder-only(BERT)
- decoder-only(GPTs,Llama)
训练
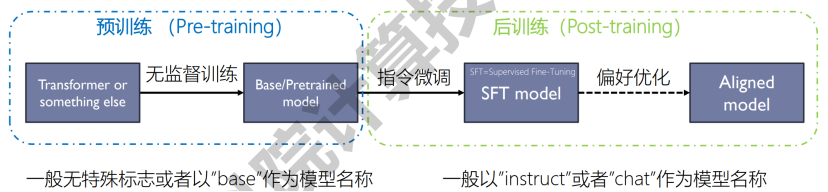
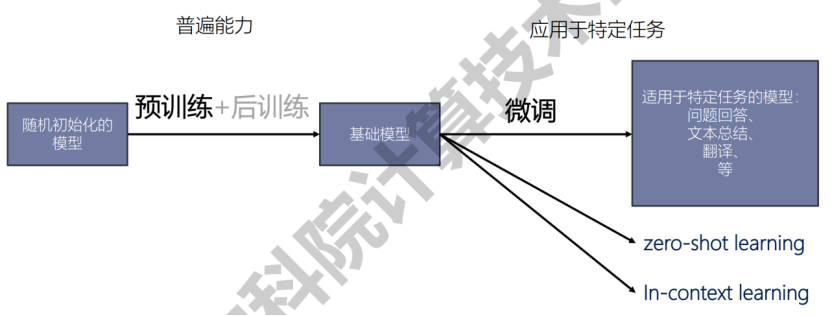
- 预训练
- 无监督训练:自回归,给定前N-1个词,预测第N个词,无需标注
- 数据处理:数据获取,数据清洗,数据打包
- 如何观测训练效果:loss曲线,测试集去重
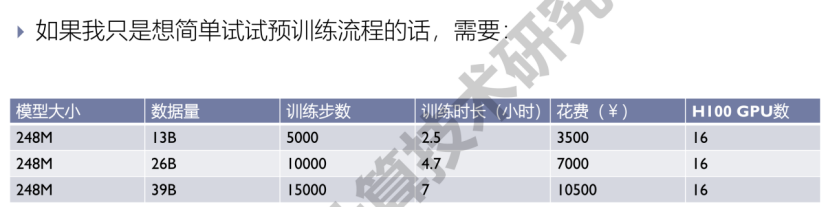
- 预训练相关数据参考!
- 尺度定律
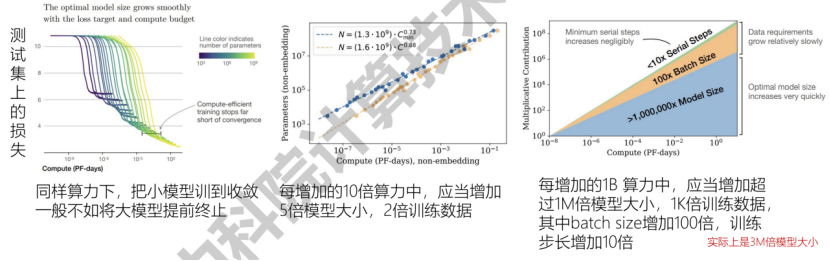
- 规模与形状:模型效果强依赖于模型大小、数据大小、算力大小(scale),而弱依赖于模型形状
- 平滑幂律:当规模(模型大小、数据大小、算力大小)中,其他两项不是瓶颈时,模型效果和剩余那一项成幂律关系(power-law)
- 过拟合的普遍性:同时增大模型大小和数据大小,模型效果会持续增加。然而如果只一味增加其中一项,模型效果就会进入衰退阶段
- 样本效率:大模型具有比小模型更高的样本效率,达到同样效果所需的样本数和训练步数更少,同样的数据量大模型可以学的更好
- 算力的最优分配:给定算力大小,如何调整模型大小和数据集大小(训练步数 x batch size)以获得最优的模型效果?
- 尺度定律的可迁移性:当训练和测试不同分布时,模型在测试集上的表现仍满足尺度定律,且模型在不同分布测试集上的表现和模型在训练分布上的表现高度相关
- 数据有限下的尺度定律:当训练数据有限时,通过重复使用数据进行训练仍然可以得到可预测的“尺度定律”
- 尺度定律的普遍性:并不只有Transformer模型具有尺度定律,但是不同模型结构的效果会有区别
- 涌现:在小模型中不具备,但在大模型中具备的能力。随着模型训练规模增加,模型的准确率发生尖锐突变<-准确率指标非线性
- 后训练
- 指令微调:收集人工标注的成对<问题,答案>数据,进行 监督训练,得到SFT modelss
- 偏好优化
- 训练奖励模型:人工给SFT model的输出做排序
- 优化策略模型:使用奖励模型和强化学习算法对大模型进行优化(Test-time scaling,pass@k,PRM > ORM > Majority Voting)
- 强化学习:?
- 自提升:?
- 微调
- 分类:增加参数微调(适配器微调,软提示微调),选择性微调(DiffPruning,Bitfit),重参数化微调(Low-Rank Adaptation,Infused Adapter by Inhibiting and Amplifying Inner Activations)
- 推理
- 解码分类(Decoding):贪心搜索,束搜索,采样,对比解码
- 解码加速:并行解码,投机解码
- 提示词prompt
- 上下文学习(In-Context Learning,ICL)
- 思维链(Chain of Thought,CoT)
- 检索增强生成(Retrieval-Augmented Generation,RAG)
大模型系统软件
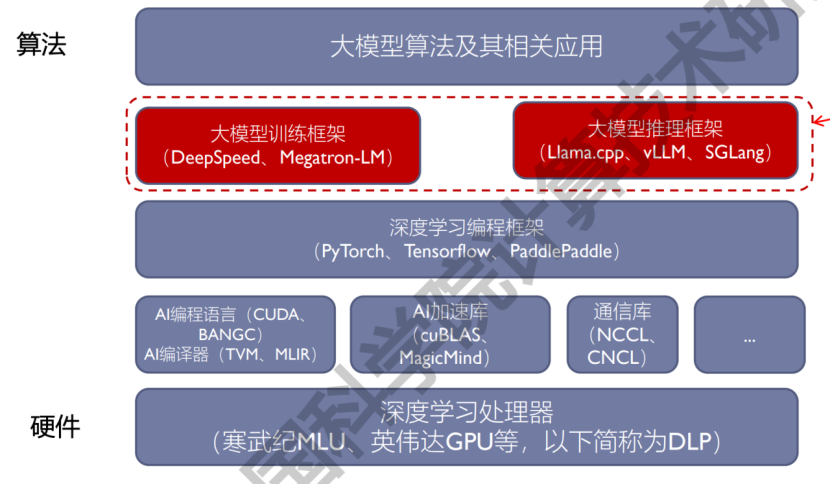
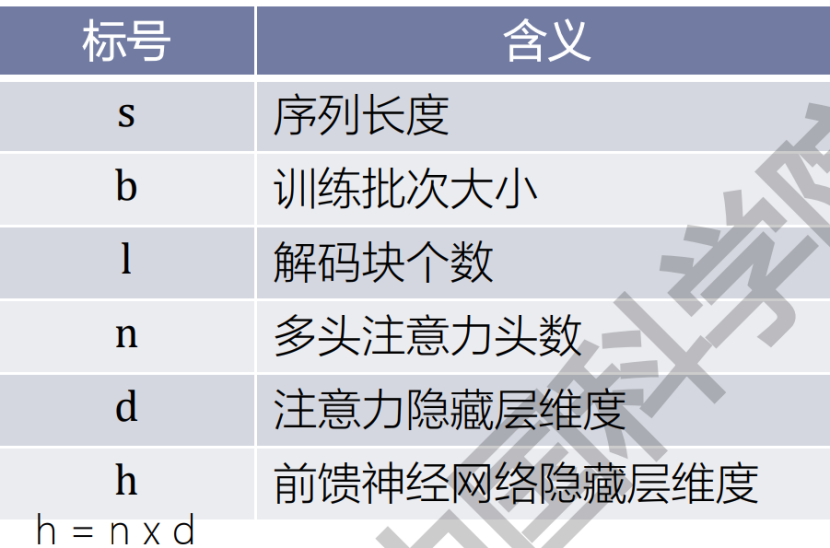
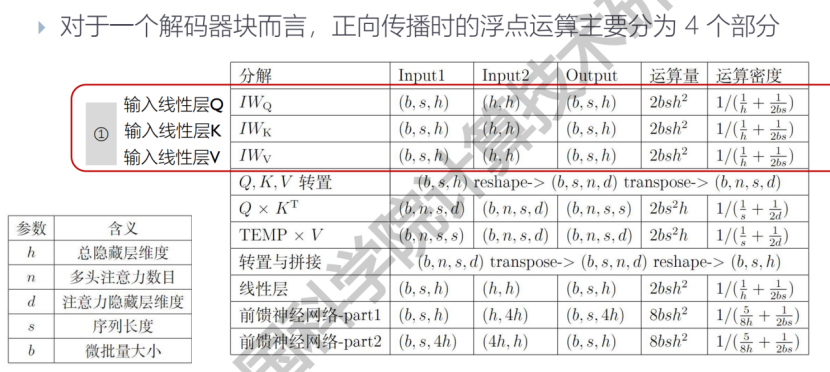
- 分布式训练
- 分布式架构:参数服务器,集合通信
- 分布式同步策略:同步通信,异步通信
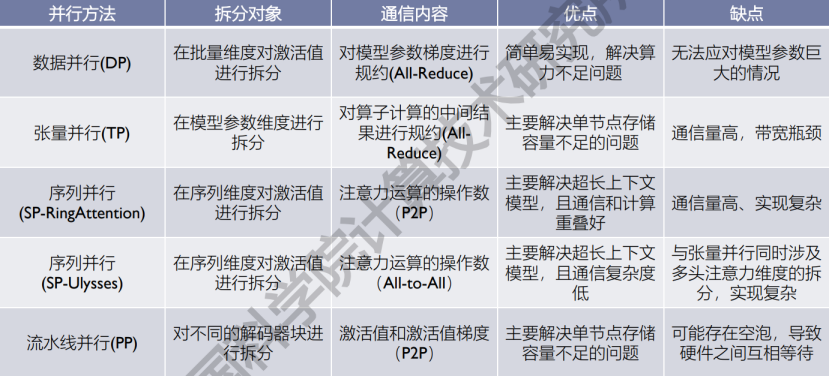
- 并行


- 计算效率优化:混合精度训练(Mixed Precision Training),稀疏化(Sparsity),注意力机制融合优化(FlashAttention)
- FlashAttention:在GPU上构造Fully-Fused的Attention算子
- FlashAttention-1:softmax的性质
- FlashAttention-2:进一步优化计算算法,并优化并行策略
- FlashAttention-3:基于Hopper GPU硬件特性的进一步优化